3.1 KMP算法
3.1.1 简介
KMP算法是一种改进的$\color{orange} {字符串匹配算法}$。KMP算法是三位学者在 Brute-Force算法的基础上同时提出的模式匹配的改进算法。Brute- Force算法在模式串中有多个字符和主串中的若干个连续字符比较都相等,但最后一个字符比较不相等时,主串的比较位置需要回退。KMP算法在上述情况下,主串位置不需要回退,从而可以大大提高效率。
3.1.2 KMP算法解决的问题模型
KMP算法算是朴素匹配算法的优化版本,在从主串中寻找子串的时候遇到主串字符数特别大,此时使用朴素匹配算法的时间复杂度就很高,但空间复杂度很低。而使用KMP算法就可以降低时间复杂度
3.1.3 介绍
1.最长公共前缀和后缀

如上图举例:
比如一个字符串:
abbccdabb
它的前缀集合为:a、ab、abb、abbc、abbcc、abbccd、abbccda、abbccdab
它的后缀集合为:b、bb、abb、dabb、cdabb、ccdabb、bccdabb、bbccdabb
可以看出来,最长的前缀和后缀相等的不就是abb吗。
所以$\color{orange} {最长公共前缀和后缀}$就是abb
2.图解KMP
第一个长条代表主串,第二个长条代表子串。红色部分代表两串中已匹配的部分,绿色和蓝色部分分别代表主串和子串中不匹配的字符。

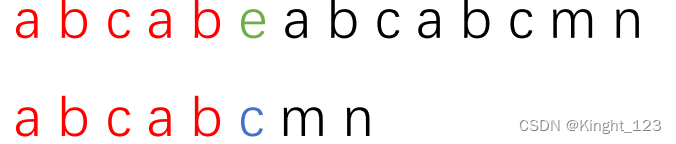
现在发现了不匹配的地方,根据KMP算法,我们要将字串向后移动,现在要确定移动多少的问题。
这个时候之前提到的最长相等前后缀就派上用场了。
可以看到原来红色部分的最长相等前缀和后缀是ab,所以字串移动的距离就是ab两个字符串的长度,移动距离为2。
移动完成的效果如图所示:

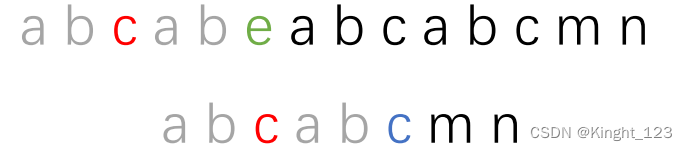
这一步弄懂了,KMP算法的精髓基本就掌握差不多了。
接下来的就是一个循环的过程,我们之前所说的,每一个字符前的字符串都有最长相等前后缀,而且最长相等前后缀的长度是我们移位的关键,所以我们单独用一个next数组存储子串的最长相等前后缀的长度。而且next数组的数值只与子串本身有关。
所以next[i]=j,含义是:下标为i 的字符前的字符串最长相等前后缀的长度为j。
所以我们可以算出来next数组的具体的数值,如下表所示:
| next[0] | next[1] | next[2] | next3] | next[4] | next[5] | next[6] | next[7] |
|---|---|---|---|---|---|---|---|
| -1 | 0 | 0 | 0 | 1 | 2 | 3 | 0 |
我们把子串移动,也就是让s[5]与t[5]前面字符串的最长相等前缀后一个字符再比较,而该字符的位置就是t[?],很明显这里的?是2,就是不匹配的字符前的字符串 最长相等前后缀的长度。
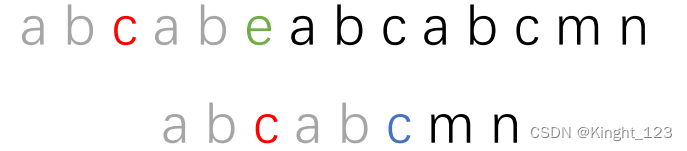
也是不匹配的字符处的next数组next[5]应该保存的值,也是子串回溯后应该对应的字符的下标。 所以?=next[5]=2。接下来就是比对是s[5]和t[next[5]]的字符。这里也是最奇妙的地方,也是为什么KMP算法的代码可以那么简洁优雅的关键。
next数组作用有两个:
- next[i]的值表示下标为i的字符前的字符串最长相等前后缀的长度。
- 表示该处字符不匹配时应该回溯到的字符的下标.
3.1.4 代码
int KMPIndex(SqString s,SqString t) //KMP算法
{
int next[MaxSize],i=0,j=0;
GetNext(t,next);
while (i<s.length && j<t.length)
{
if (j==-1 || s.data[i]==t.data[j])
{
i++;j++; //i,j各增1
}
else j=next[j]; //i不变,j后退,现在知道为什么这样让子串回退了吧
}
if (j>=t.length)
return(i-t.length); //返回匹配模式串的首字符下标
else
return(-1); //返回不匹配标志
}引用:



